



How do we actually do process mining
Much discussion around process mining centres on the algorithms and technical methods used to analyse data and to visualise the analysis results.
But practitioners need to think seriously not just about these issues but also about the broader methodologies into which these tools and techniques are embedded – or the process of process mining.
There have been limited but important contributions by both researchers and practitioners in this space including the ‘L star’ process mining project methodology which is summarised in the following figure.

Adapted from: Process Mining: Discovering and Improving Spaghetti and Lasagna Processes
But the experience of process mining for many practitioners is that real process mining projects can be much more challenging than the neat sequence of steps above might suggest. Indeed, the process of process mining itself has bottlenecks!
The good news is that both researchers and vendors have recognised these challenges and many new tools are emerging which can assist us in alleviating these bottlenecks and streamlining the process of process mining. This blog post will explore some of these developments.
Streamlining the process of getting data
While the data requirements for process mining are relatively trivial and easily explicable, actually getting hold of the data, including at the right level of granularity, can be a challenge.
And the need to involve expensive technical resources like database and reporting analysts to get this data can be a further challenge.
Process mining tool vendors are responding to these realities by adding functionality to enhance the ease with which process data can be accessed by end users.
Fluxicon Disco – Airlift
One such example is Airlift which aims to enable Disco users to retrieve process data whilst minimising the intervention of these expensive technical resources.

From Fluxicon Blog – Disco 1.7.0
Airlift does this by providing the following functionality:
- A user-friendly user interface to enable non-technical users to request process data from within Disco;
- Translating the user request and passing it through an appropriate interface to back-end data sources; and,
- Passing the returned data directly into the Disco tool for analysis.
While this approach likely still requires technical resources to configure the initial data extracts and the interfaces to airlift, the advantage is that once these are configured, business users can independently retrieve and analyse updated data extracts on an ad hoc basis.
Celonis system integrations
When we talk about extracting process logs we often really mean going hunting in the data structures of sometimes very complex applications to find events captured in the data which correspond to steps in the business process we are looking to analyse.
One of the reasons we require expensive technical resources with good application knowledge to do process mining is precisely to create and validate such mappings.
The approach by Celonis Process Mining to streamlining access to process mining data is to create standardised mappings for a number of the most popular enterprise applications including Oracle, SAP and HP.

From Celonis Process Mining IT Systems
This may be attractive in particular for smaller organisations which lack the resources or capability to extract, validate and transform their application data to enable it to be process mined.
Streamlining the process of analysing data
But it’s not just the provision of data that we can look to streamline.
Apart from our initial analysis of a new data set, we often want to repeat the same analysis on a similar or updated data set to one that we’ve already analysed. This might be to check if problems we’ve identified are persisting or if problems we thought we’d fixed are still occurring.
In this situation, it can be time consuming to perform the same data transformations and tool configurations each time we want to do this.
A number of tools are available which fully or partially automate process analysis. While they’re not all enterprise-ready, they provide some great insights as to how such functionality might be implemented and more generally how process mining tools might evolve in future.
RapidProM
RapidMiner is a very popular visual programming environment for data analysis. The following image shows the way that RapidMiner users can assemble analysis components into analysis workflows by ‘piping’ outputs between different components.

From RapidMiner
RapidProM was presented at BPM 2014 by Ronny Mans. It extends the standard RapidMiner tool by incorporating around 40 ProM plugins which users can assemble into process mining workflows.
The following is an example ProM workflow which reads a log file, mines a process model and then checks the conformance of the model against the log.
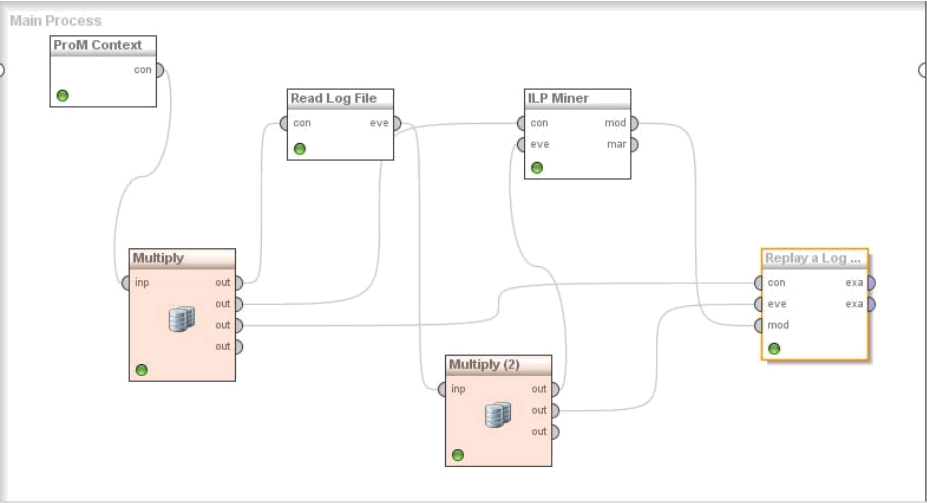
From RapidProM User Guide
Once we’ve assembled such a workflow we can run it by hitting the play button. We can save it and run it later. And we can share it with other users.
And because RapidProM extends an existing data analysis tool we can use standard RapidMiner functions including statistical and data analysis functions along with ProM functions to do more sophisticated forms of process analysis than is supported by current process mining tools.
The popularity of RapidMiner suggests there is strong demand for code-free interfaces for data analysis – which in turn suggests that a similarly large proportion of process mining practitioners are potential RapidProM users.
PMLAB
While RapidMiner offers a compelling illustration of how process mining automation might be implemented, it’s also true that the visual programming paradigm of RapidMiner is unlikely to appeal to everyone.
PMLAB was presented at BPM 2014 by Josep Carmona and takes a slightly different approach to process mining automation.
PMLAB implements a number of core process mining functions into the python programming language. This enables the authoring of short python scripts by which these functions can be chained together to create process mining workflows.
Shown below is a simple script in which a very simple log is created and a BPMN model is mined from that log.
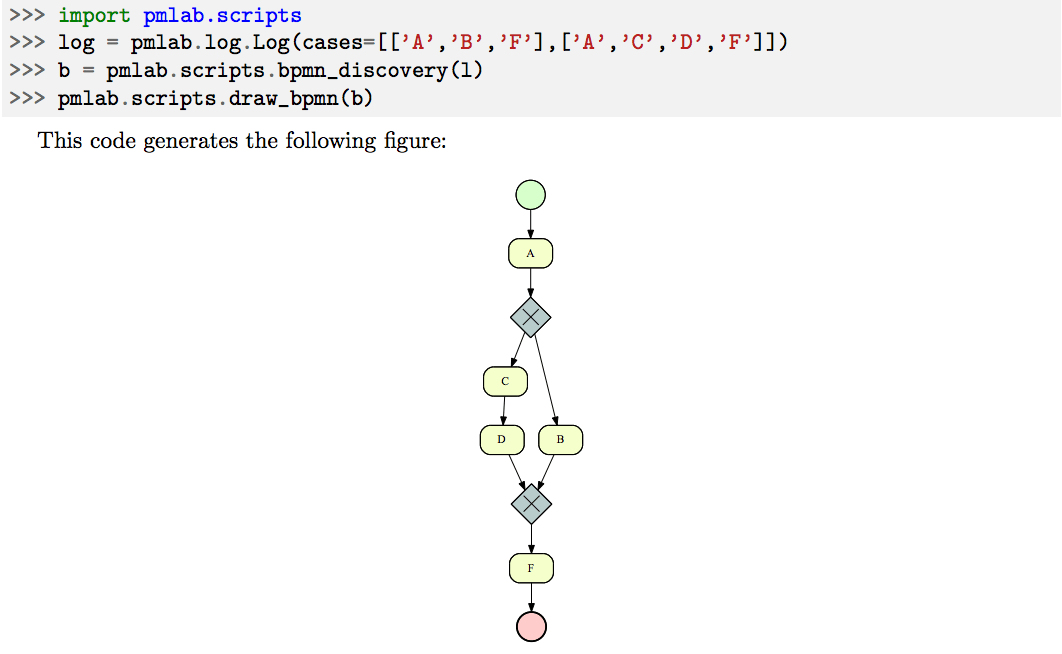
From PMLAB User Guide
The code-driven analysis paradigm of PMLAB clearly distinguishes it from the point and click user interfaces of popular existing process mining tools like ProM and Disco. And it obviously limits the accessibility of PMLAB for a significant group of process mining practitioners – i.e. business users and non-technical analysts.
But for people from data mining, statistics and machine learning backgrounds who are already familiar with languages like Python and R, incorporating process mining tools into these languages may be preferable to learning a new tool.
And given Python is the fastest growing tool among the large and growing data science community, its arguable that the availability of robust process mining tools for Python would increase the uptake of process mining among this community.
Fluxicon Disco – Recipes
While not offering full process mining automation, Disco includes functionality for reusable log filters which can accelerate process mining and hence are worth exploring in this context also.
Filters in Fluxicon Disco allow for the filtering of logs being analysed using combinations of both process criteria (eg ‘include only cases where activity B follows activity A’) and attribute criteria (‘include only cases from region C’).
Such filters are very powerful tool for comparing different logs and different views or aspects of a single log.
But such filters can take some time to configure and once we’ve configured and applied them to a particular data set we often want to share them, reuse them later or apply them to different data sets.
Recipes enable us to do just this. The following figure shows an example of a recipe within Disco. Note in particular the options to favourite and export the recipe.

Disco recipes are certainly a great tool for rapidly asking the same or similar questions of new data sets and hence for accelerating the data analysis process.
And because they can be accessed through Disco’s existing point and click user interface, of the three tools presented, they are clearly the most accessible option for accelerating process mining for existing ProM or Disco users.
Where to from here?
I hope the above highlights have demonstrated that streamlining the process of process mining is a very fast moving space with some very exciting contributions from researchers and vendors alike.
But I’ve only really scratched the surface – so I’d love to learn more about other tools or approaches beyond those discussed in this post.