



The ‘spaghetti’ problem
One of the most perplexing outcomes for new process miners can be generating a ‘spaghetti model’!
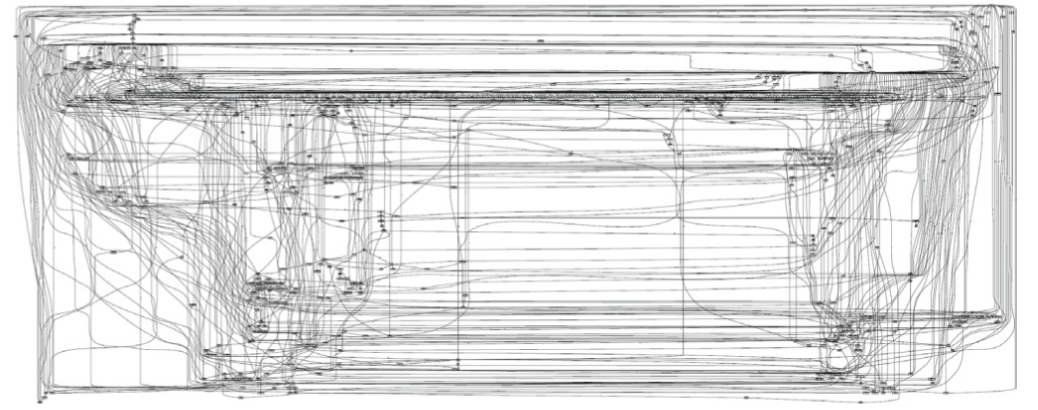
From Wil van der Aalst – Process Mining – Chapter 12 – Analyzing Spaghetti Processes
You can see above that such models take their name from the proliferation of events and flows which make the model practically unreadable.
While there are approaches to minimising the issue, including by filtering event logs before or during analysis, there may still be limitations with existing process mining approaches and such that while we can minimise the ‘spaghetti’ problem we may not be able to entirely eliminate it.
“Empty the dishwasher, mop the floor and put out the garbage!”
One such limitation is that most approaches to managing processes to date (including process mining) typically emphasise the specification of a sequence of activities comprising a process and the order in which these activities MUST be completed.
Because not only the goal of the process but also how this goal is arrived at are prespecified such approaches can be described as imperative.

More recently, a perceived misalignment has been identified between such approaches and the rise of knowledge work in which workers increasingly use judgement to decide for a particular case which activities need to be completed and in what order.
“Clean the kitchen. Just don’t touch the stove!”
A key tool in this emerging space is declarative process modelling which is contrasted by proponents with traditional imperative approaches.
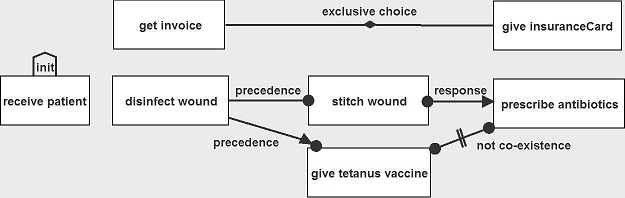
From Technische Universiteit Eindhoven (TU/e)
While the notation in the above diagram may be unfamiliar, you can see that..
- The activities aren’t simply connected into a single sequence of activities. What this means is that the health worker can choose to perform the medical subprocess medical and the financial subprocess in whichever order is most appropriate each time the process is performed.
- There are also many different types of connectors between the activities and these specify a range of different relationships between activities beyond simply arrows indicating the order in which the activities are performed. E.g. the ‘not co-existence’ flow between ‘give tetanus vaccine’ and ‘prescribe antibiotics’ specifies that if the health worker performs one of these activities, they shouldn’t then perform the other.
Thus a declarative model specifies only constraints on how the process can be performed without attempting to specify exactly how the process should be performed.
Because there are ordinarily relatively fewer constraints on how a process is performed than individual steps performed in a process this should result in less complicated models which are easier for everyone to understand, right?
And by combining this approach with process mining we should be able to generate models from process data which are not only simpler but which also reflect the actual process performed rather than just the process as designed, right?
OK lets try it
The following is an example of applying declarative process mining to real world data:
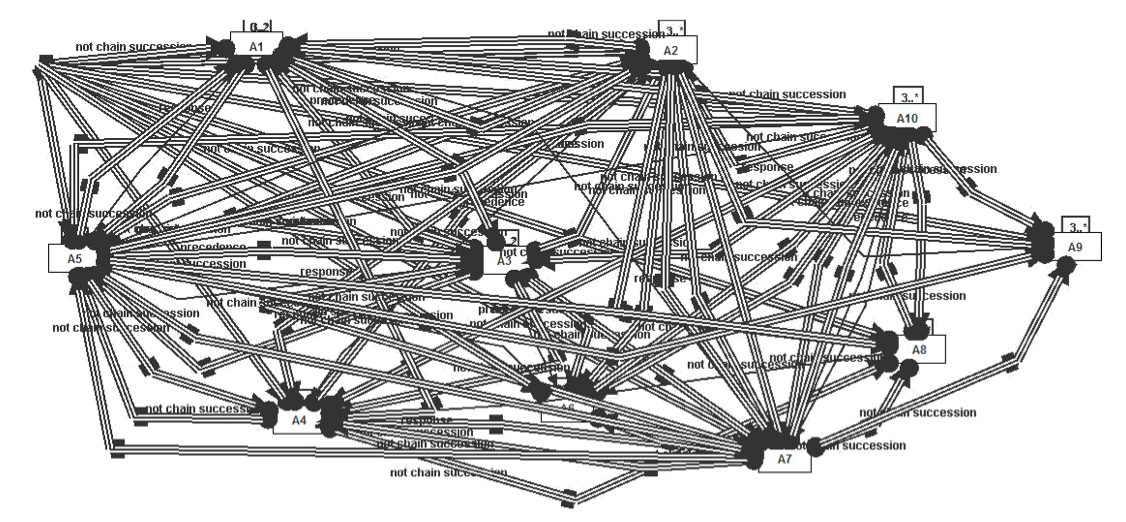
So what happened? For starters the number of constraints inferred from the real world process data seem to increase rapidly with the number of steps in the process.
But perhaps also real world processes may have both declarative and imperative elements. And a purely declarative process mining approach may be a poor fit for constructing models of such processes.
So whats new?
Work by Tijs Slaats, Hajo Reijers and Fabrizio Maggi presented at BPM 2014 involved the development of a hybrid process mining method. Ie combining both imperative and declarative approaches.
Firstly, the following is a process model generated from a real world process data set using a popular imperative process mining algorithm:
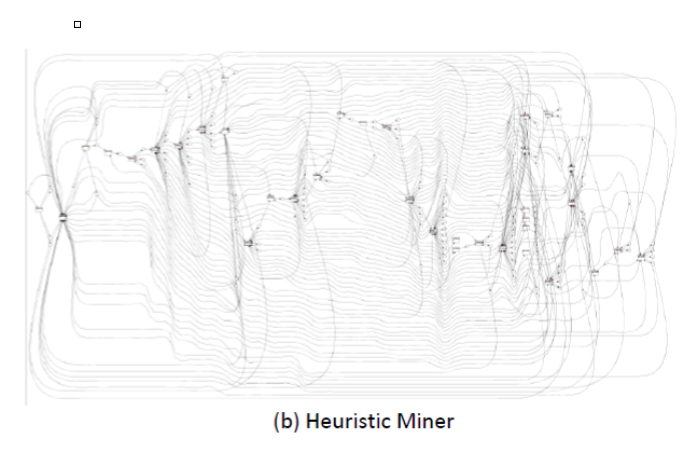
From Tijs Slaats, Hajo Reijers and Fabrizio Maggi – The Automated Discovery of Hybrid Processes
The result is a familiar ‘spaghetti’ model.
However, the next diagram is a process model generated from the same data set using the hybrid process mining approach.
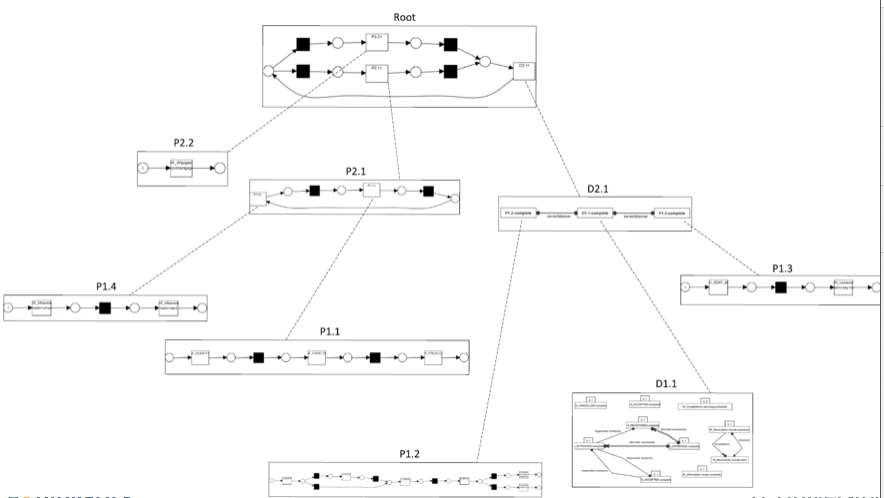
From Tijs Slaats, Hajo Reijers and Fabrizio Maggi – The Automated Discovery of Hybrid Processes
The hybrid approach generates a much simpler process model than the imperative process mining approach.
And it does this by neatly decomposing the process into a hierarchy of processes each of which can be either imperative (e.g. Root) or declarative (e.g. D2.1).

From Tijs Slaats, Hajo Reijers and Fabrizio Maggi – The Automated Discovery of Hybrid Processes
What’s the potential business impact?
Given that business users find simpler process models much more comprehensible and engaging, if these initial results can be replicated more widely, hybrid process mining has the potential to significantly enhance the value of mined process models to business users.
So what’s next?
It would be great to see further testing of this approach against a broad range of process logs to confirm whether the approach can be expected to generate much simpler models more generally.
Further, evaluating process mining algorithms typically involves checking them against four competing criteria: Fitness, simplicity, precision, and generalization. Such analysis for the hybrid approach would demonstrate that the gains in simplicity achieved by the hybrid approach are not simply at the expense of other evaluation criteria.
Similarly performance will be a significant determinant of the usefulness of this approach in the real world. So performance benchmarking against the existing algorithms would be good to see also.